On how to regularly use regular expressions.
Published:There's little to zero chance that you're either a). computer scientist or b). web developer or even c). computer enthusiast, and haven't came across or at least heard of regular expressions.
But unless you have a computer science fundamental background, or you're doing math for fun, or anything in betweet
- being said with one word: you're normal (no tech geek or anything related), you're either having, but not limited to a headache, stomach itchiness and/or some level of uncomfortableness when dealing
with odd sequences of characters, such as:
var parse_url = /^(?:([A-Za-z]+):)?(\/{0,3})([0-9.\-A-Za-z]+)(?::(\d+))?(?:\/([^?#]*))?(?:\?([^#]*))?(?:#(.*))?$/;
It wasn't until recently that I digged a little deeper into regular expressions. I came across a few great articles or in-book chapters on that subject, such as:
- Chapter 7, Regular Expressions in Javascript: The Good Parts by Douglas Crockford,
- A sub-chapter, Regular expression in a book titled Speech and language processing by Daniel Jurafsky & James H. Martin.
- If you speak Slovene, I highly recommand you Perl RegEx by Andraz Tori (written in Slovene).
The Regular Expression Syntax table below, which I use as a cheat-sheet was a real eye-opening for me. It is broken down into the smallest units, expressions, which are easy to understand.
| Expression | Description | Examples and expansions |
|---|---|---|
| Single character expressions | ||
| . | any single character | spi.e matches "spice", "spike", etc. |
| \char |
for a nonalphanumerical char, matches char literally |
\* matches "*" |
| \n | new line character | |
| \r | carriage return character | |
| \t | tab character | |
| [...] | any single character listed in the brackets | [abc] matches "a", "b", or "c" |
| [...-...] | any single character in the range | [0-9] matches "0" or "1" ... or "9" |
| [^...] | any single character not listed | [^sS] matches one character that is neither "s" nor "S" |
| [^...-...] | any single character not in the range | [^A-Z] matches one character that is not an uppercase letter |
| Anchors/Expressions which match positions | ||
| ^ | beginning of the line | |
| $ | end of the line | |
| \b | word boundary | nt\b matches "nt" in "paint" but not in "pants" |
| \B | word non-boundary | all\B matches "all" in "ally" but not in "wall" |
| Counters/Expressions which quantify previous expressions | ||
| * | zero or more of previous r.e. | a* matches "", "a", "aa", "aaa",... |
| + | one or more of previous r.e. | a+ matches "a", "aa", "aaa",... |
| ? | exactly one or zero of previous r.e. | colou?r matches "color" or "colour" |
| {n} | n of previous r.e. | a{4} matches "aaaa" |
| {n,m} | from n to m of previous r.e. | |
| {n,} | at least n of previous r.e. | |
| .* | any string of characters | |
| (...) |
grouping for precedence and memory for backreference |
|
| ...|... | matches either of neighbor r.e.s | (dog)|(cat) matches "dog" or "cat" |
| Shortcuts | ||
| \d | any digit | [0-9] |
| \D | any non-digit | [^0-9] |
| \w | any alphanumeric/underscore | [a-zA-Z0-9_] |
| \W | any non-alphanumeric | [^a-zA-Z0-9_] |
| \s | whitespace (space, tab) | [\r\t\n\f] |
| \S | non-whitespace | [^\r\t\n\f] |
This cheat-sheet table is from the book Speech and language processing by Daniel Jurafsky & James H. Martin. If you want just the cheat-sheet table, it's avaliable here.
Above, there is a table I really wish someone would introduce me to at the time I came across with regular expressions.
Syntax being broken down in fundamental units is way more readable and understandable.
That way you can start applying simple syntax and add up to form real complex examples as seen in the top of this article.
Learning curve might be steep, but the outcome is tremendous!
Two simple examples
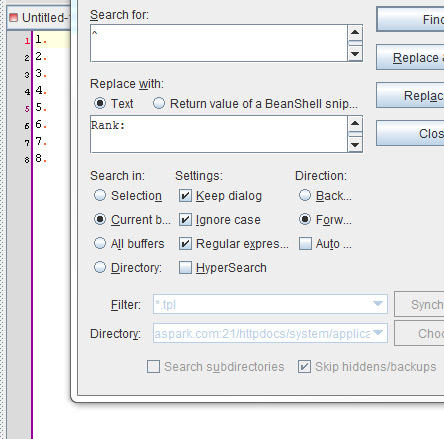
Let's assume you do use a text editor that supports regular expressions. Imagine you have a list of numbers or strings that you need to prepend or append something (number, or string).
You can do that by hand, which is probably quicker if your list is relatively small. But as the list grows longer, regular expression is your friend.
Use expression ^ to match the beginning of the line or $ to match the end of the line and replace it with whatever you want to replace it with.
The example on the right image does just that. It searches for the beggining of the line and replaces it with "Rank:", so it basicaly prepends the desired string.
Example below is pretty common.
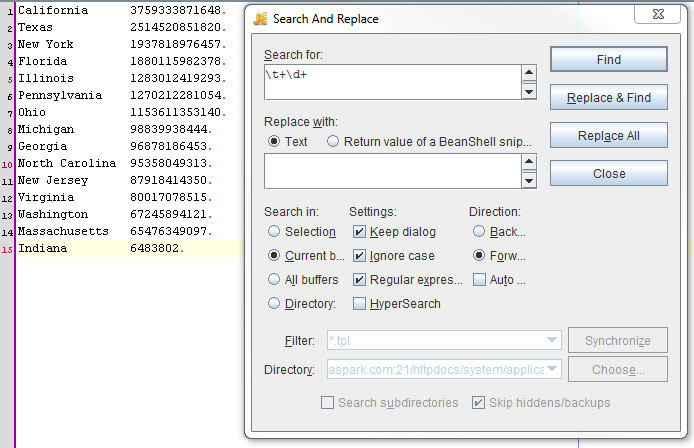
Each row contains a string (in our case, the name of a U.S. state) and some number (its census population). Presume the number is not relevant to us, so we want to delete it.
We use expression \t which indicates tab character and a sign +, which stands for "one or more of previous r.e."
(in our example, a number is separated from the state with one or more tabs).
To search for digits, we use \d, which is a shortcut for "any digit" from 0 to 9.
Alternatively, we could use [0-9]. We use + again, because there are few digits that represent census population of each state.
 If we were only interested in census population, the regular expression to search for U.S. state names would probably be:
[a-z\s]+\t+.
If we were only interested in census population, the regular expression to search for U.S. state names would probably be:
[a-z\s]+\t+.
Do you often work with lots of data? Do you use regular expressions at all? If so, when, where and how often? However, if you do, I would recommend you to take a look at Google Refine, which is a powerfull tool for working with messy data, cleaning it up, transforming it from one format into another, extending it with web services, and linking it to databases like Freebase.